JJUG CCC 2009 fall に行ってきました
スーパー台風が直撃し、山手線をはじめ主要交通機関が全面的にストップするなか、CCC は午前中 30 分遅れになったものの、基本的につつがなく進行。すごいよ。
頓知・の井口さんの基調講演に何とか滑り込み、セカイカメラの野望を聞きながら、会場にペタっとエアタグを貼ったりしていました。 :-p
午後のセッション最初の、日経BP社 / 日経コンピュータの中田敦さんのお話が個人的にはとても楽しかったので、少し詳しめにメモを残しておきます。
# 聞き間違いや勘違いがあるかもしれないので、ご容赦ください。
データセンター視点で比較したクラウドの内側
- 中田さん
- 問題意識
- なぜクラウドを使うのか
- 安いからというのは誤解
- クラウドが提供するアプリのほうが、PC のアプリより優秀だから
- CPU もメモリもディスクもすべて性能が上
- 検索エンジン、Google Maps、...とかローカルアプリとして実現しようとしたら大変だよね
- Web ブラウザ以外での利用も可能に
- Google が提供するアプリケーションはなぜ高速なのか?
- サーバ生産台数
- Google の先進性
- 2006年に Project Black Box を Sun が発表したとき誰が使うの?と思ったが、
- 実は 2005年 11月から Googleはすでに運用していた!?
- 去年の今頃には、潮力発電の水上型データセンターの特許をとっている...
- もうできつつあるのかもしれない
- 電力利用効率
- 影響を受けているのはマイクロソフト
- MS のシカゴのデータセンター
- シカゴのデータセンターの規模感
- 日本の年間のPCサーバの出荷代数 55万台
- シカゴデータセンター、30 - 40万台
- 50M ワットの年間電気料金は 110億円 (東京電力)
- 1サーバあたり、100-150 ワット
- ATOM とか ARM とか
- The Data Center as a Computer
")
- 作者: Luiz Andre Barroso,Urs Holzle
- 出版社/メーカー: Morgan and Claypool Publishers
- 発売日: 2009/08/15
- メディア: ペーパーバック
- クリック: 17回
- この商品を含むブログ (2件) を見る
- チラーレス
- Google のベルギーのデータセンタはチラータワーがない
- 高いとこに水を運んで落とすことで気化熱で冷ます、これがチラータワー
- ベルギーみたく水が豊富なとこではそれが不要
- 川から水をひいてあっためたまま返すのかな? (^^;
- さらに、寒いとこにデータセンターつくることで冷却コストなしにしようとしてる
- 逆に、冷やす必要はない!?
- サーバの管理
- 自前主義
- 一番大事なデータセンターのプロパティはオープンにしてない
- Android はある意味どうでもいい部分
- 「巨大なクラスタを保有しないサードパーティ、ソフトウェア、プロバイダがソフトウェアのテストやチューニングを十分な水準で行うのは困難だ」
- OS レイヤがあるとしたら、それは「Cluster-Level Infrastructure」のことだ
- Linux は OS だと思ってない?
- ProLiant の価格性能比は、SuperDome の4倍
- どんな大きな SMP サーバでも1台ではまかないきれない
- レイテンシはLANに集約されるので、SMP サーバを利用するのは無駄
- プロセッサ使用率が高いほど消費電力効率が良い
- つまり、安い遅いほうがよい
- Google にとっての障害 (上から順に重い)
- 喪失、データが再生成できない
- 未到達、サービスがダウン
- 劣化、サービスは使えているが劣化している状態
- 隠蔽、S/W H/W で問題をカバーできてる状態
- Salesforce CTO

Redmine で添付ファイルはデータベースに格納しないの?
先日の記事でもちょっと書いていましたが、Redmine ではチケットへの添付ファイルや文書の登録、また Wiki に貼り付けた画像やその他の添付ファイルは、REDMINE_ROOT 以下の files フォルダに格納されます。
チケットへの添付ファイルの追加
- (snip)
- 添付ファイルは REDMINE_HOME のfiles 以下にファイル名に prefix をつけて格納される
- これは文書やそれ以外での添付のときでも同じ
改めて考えてみると、添付ファイル等だけがディスクで管理されるのは、以下の問題があるようにも思えてきます。
データベースだけでなく files 以下も忘れずにバックアップしないといけないのは微妙に面倒ですし、クラスタを組んだ場合にローカルディスク管理の添付ファイルをほかのインスタンスからどう参照するか? といった問題もついてまわります。
Redmine.JP で「Apache上でRuby on Railsアプリケーションを動かす/Passenger(mod_rails for Apache)の利用」なんて記事も見かけましたが、複数インスタンスを並列稼働させることによるレスポンスの改善には言及されているものの、添付ファイルまわりの解決についてはとくに触れられてなかったりします。
で、こんなことはすでに誰かが考えてるだろうと思って、Web を漁ってたらフォーラムで次の投稿を見かけました。
Adding the attachments to the database means one entity to backup, one entity to restore (or migrate). Also allows redmine to be proxied across machines in a cluster for load balancing without doing special filesystem sharing.
2008年の4月頃に起票されて、すでにクローズとなっているチケットです。 (^^;
上記のとおり、添付ファイルもデータベースに格納できるようにしてほしい、といった要望なのですが、
... ここから抜粋 & 適当訳 ...
The idea of storing files in the db may have some merit, but this is clearly a design decision and not a defect.
添付ファイルをディスクに管理するようにしたのは、設計上の判断。
This would make an excellent feature as a configurable option for the reasons Carl mentioned.
設定オプションで切り替えられるってのはいいね。
Storing standalone files in databases is just totally missing the point of what filesystems are made for. I admit one might like the idea of a single-point, network-enabled, access to all the data. But putting blobs in the DB is a poor design, really. Jean Philippe was right in his design.
If you want single-point access to the data, accessible through network, do not put blobs in the DB, this will not be the correct design. Better write an abstraction client/server layer, let's call this a proxy, between RedMine data access and actual data storage. You might find inspiration from the ZEO / ZODB design for Zope, although I would not recommend to mimic it entirely.
DB に blob でただつっこむってのはイケてない設計だよ。
ネットワーク越しにアクセスできるようにしたいなら、blob につっこむのは正しい設計じゃない。クライアント/サーバーな抽象化層を挟んだほうがよいよ。Redmine のデータアクセスと実際のデータストレージ間のプロキシと呼べるもの。この発想は Zope の ZEO / ZODB からも得られるよ。ただ真似するってのはおすすめじゃないけどね。
I can think of a lot of good reasons to not toss files into the database:
- It balloons the db size, making backups take longer.
- It puts extra work on the db, which has plenty to do as is.
- It means files would have to be serialized through rails (because there is no file for the webserver to point to) -- which means that rails process will block incoming web requests while the file is being downloaded. There are ways around this, but they are really hackish, or don't lend well to simple deployments.
- There are a ton of database "gotchas" that ActiveRecord can't abstract away when dealing with blobs.
Plus, backing up files is exceedingly easy. Just rsync them to another box. I admit it might not be blatantly obvious that you need to do it, but I think that's a point for documentation rather than creating a ton of work with little real-world benefit.
If you need single-point access to the data over a network, just use a NFS/SMB share. It is plenty fast for attachments.
ファイルをデータベースに格納しないほうがよい理由がたくさん思いつくよ。
DB のサイズも増えるし、その分バックアップ時間もかかる。余計な仕事を DB にさせたくない。ファイルは Rails でシリアライズされることになるし、ファイルがダウンロードされてる間は Rails プロセスもブロックされる。AR は blob を抽象的に扱えない、とかね。
ファイルをバックアップするのはずっと簡単。別筐体に rsync すればいい。複数インスタンスをたてた場合は、NFS や SMB で共有すればいいじゃん。速いしね。
If it's a bad idea, then I suggest dropping the feature. If so, I'll file feature request for configurable storage location and a backup script that backs up the db, attachment files, and configuration to some specified location.
格納場所を設定可能するとか、DB / 添付ファイル / 設定ファイルなどをバックアップするスクリプトがほしいよ。
I've added a few words about this at the end of RedmineInstall guide.
(そんな感じのスクリプトを) Redmine インストールガイドの最後にちょっと追記しといた。
... ここまで ...
ってな感じでチケットはクローズしています。
実際、インストールガイドを見てみると、こんな感じ。
Installing Redmine
Backups
Redmine backups should include:
- data (stored in your redmine database)
- attachments (stored in the files directory of your Redmine install)
Here is a simple shell script that can be used for daily backups (assuming you're using a mysql database):
# Database
/usr/bin/mysqldump -u-p | gzip > /path/to/backup/db/redmine_`date +%y_%m_%d`.gz # Attachments
rsync -a /path/to/redmine/files /path/to/backup/files
我が家に iPhone がやってきました
RubyKaigi2009 の懇親会で散々 Bump してる姿を見せつけられた結果、やっぱり欲しくなって稟議を通してしまいました。 (^^;

ケースはひとしきり悩んだ結果、シンプルなところに落ち着きました。で、...
- ケースとフィルムの装着
- iPhone の OS バージョンアップ
- Wifi の設定
- Gmail のアカウント設定
- 電話帳のコピー
- 必要そうなアプリをどどっとインストール
- アプリの並び替え (今デフォを含めて 80 個くらい)
- 怖くなってパスコード導入..
- twitter が楽しくなってきた
- iPhone SDK 導入
- 何かつくってみたくなってきた ← いまここ
な感じです。
# SnowLeopard もほしいな...

SHIELD iShell for iPhone 3G/3GS シェルカバー マット・レッド
- 出版社/メーカー: SHIELD
- メディア: エレクトロニクス
- 購入: 1人 クリック: 18回
- この商品を含むブログ (2件) を見る

パワーサポート アンチグレアフィルムセット for iPhone 3G PPC-02
- 出版社/メーカー: パワーサポート
- 発売日: 2008/08/19
- メディア: エレクトロニクス
- 購入: 90人 クリック: 990回
- この商品を含むブログ (40件) を見る
- あとでやる
- 契約プランの変更
- キャンペーン特典の適用
9arrows を (MySQLで) 試してみました
本家から 9arrows の最新版を落とし、対応するバージョンの Rails も入れておきます。データベースには PostgreSQL を使用するみたいですが、今回は MySQL で強引に動かしてみます。
% svn co http://9arrows.googlecode.com/svn/trunk/ 9arrows % gem install rails -v 2.1.0
早速、database.yml を書き替えて、rake コマンドをたたきます。あ、その前に MySQL にデータベースも用意しないといけないですね。
development: adapter: mysql database: 9arrows_development username: root password: host: 127.0.0.1 (snip)
% mysql -u root -p mysql> create database 9arrows_development; mysql> create database 9arrows_production; mysql> create database 9arrows_test; mysql> exit; % cd 9arrows % rake db:schema:load
rake コマンドの結果を見るに、テーブルの作成はうまくいってますが、初期データの登録で失敗しているっぽいです。そこで、schema.rb の中で execute で呼ばれている中身を手動インサートすることにします。ちなみに、datetime のフォーマットが PostgreSQL と微妙に違うのか、そのままだとインサートできなかったで、ちょこっとだけ手を加えてました。
-INSERT INTO mst_messages VALUES (2, 'project_name', 1, 'プロジェクト名', 'プロジェクト名', 'プロジェクト名', 'プロジェクト名', 1, NULL, '2007-07-08 19:32:00+09', NULL, '2007-07-08 19:39:20.984+09'); +INSERT INTO mst_messages VALUES (2, 'project_name', 1, 'プロジェクト名', 'プロジェクト名', 'プロジェクト名', 'プロジェクト名', 1, NULL, '2007-07-08 19:32:00', NULL, '2007-07-08 19:39:20.984');
作成したデータベースに流し込みます。
% rake db:schema:load > insert.sql (上述のようにちょっといじって...) % mysql -u root -p mysql> use 9arrows_developemt; mysql> charset utf8; mysql> source insert.sql; mysql> exit;
"ERROR 1366 (HY000): Incorrect string value" あたりのエラーがでて、うまく行かなにようなら文字コードの確認を。
mysql> show variables like 'character%'; +--------------------------+-------------------- | Variable_name | Value +--------------------------+-------------------- | character_set_client | utf8 | character_set_connection | utf8 | character_set_database | utf8 | character_set_filesystem | binary | character_set_results | utf8 | character_set_server | utf8 | character_set_system | utf8
さて、このままだと auto increment な id が増えていないと思うので、sequence の current 値を変更しようと setval あたりを呼びたいなぁと思ったのですが、そんな関数はないと怒られます。
mysql> SELECT setval('mst_messages_id_seq', max(id)) FROM mst_messages;
ERROR 1305 (42000): FUNCTION 9arrows_development.setval does not exist
あれれっ?と思い、ひとしきり調べてみましたが、どうやら MySQL では扱えないようです。どうしようかなぁ..と思うものの、show table status で確認してみると、ちゃんと auto increment されているではないですか!?
MySQL では、あえて弄らんでもよかったらしいです。 (^^;
mysql> show table status; +-------------------+------+----------------+-------------+----------------+ | Name | Rows | Avg_row_length | Data_length | Auto_increment | +-------------------+------+----------------+-------------+----------------+ | dat_calls | 0 | 0 | 16384 | 1 | | dat_callusers | 0 | 0 | 16384 | 1 | | dat_eventfiles | 0 | 0 | 16384 | 1 | | dat_events | 0 | 0 | 16384 | 1 | | dat_eventusers | 0 | 0 | 16384 | 1 | | dat_milestones | 0 | 0 | 16384 | 1 | | dat_mylogcmts | 0 | 0 | 16384 | 1 | | dat_mylogs | 0 | 0 | 16384 | 1 | | dat_projectcomps | 0 | 0 | 16384 | 1 | | dat_projectlogs | 0 | 0 | 16384 | 1 | | dat_projects | 0 | 0 | 16384 | 1 | | dat_projectusers | 0 | 0 | 16384 | 1 | | dat_taskcmts | 0 | 0 | 16384 | 1 | | dat_taskfiles | 0 | 0 | 16384 | 1 | | dat_taskhistories | 0 | 0 | 16384 | 1 | | dat_tasks | 0 | 0 | 16384 | 1 | | dat_taskusers | 0 | 0 | 16384 | 1 | | mst_compositions | 29 | 564 | 16384 | 30 | | mst_messages | 175 | 374 | 65536 | 198 | | mst_templates | 2 | 8192 | 16384 | 3 | | mst_tpevents | 3 | 5461 | 16384 | 4 | | mst_tpmilestones | 4 | 4096 | 16384 | 5 | | mst_tptasks | 22 | 744 | 16384 | 23 | | mst_users | 1 | 16384 | 16384 | 2 | +-------------------+------+----------------+-------------+----------------+ 24 rows in set (0.02 sec)
ということで、問題ないようなので気を取り直して起動してみます。
# 必要があれば、test、production 環境も同様に設定を。今回は development だけで進めます。
% ruby script/server => Booting Mongrel (use 'script/server webrick' to force WEBrick) => Rails 2.1.0 application starting on http://0.0.0.0:3000 ... DEPRECATION WARNING: config.action_view.cache_template_extensions option has been deprecated and has no affect. Please remove it from your config files. See http://www.rubyonrails.org/deprecation for details. (called from send at c:/ruby/ruby-186-25/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/initialize r.rb:455)
なんてログが出てきますが、とりあえず無事起動したようです。
http://localhost:3000/ にアクセスすると、ログインID/パスワードを指定してログインするか、新規ユーザーを登録することになります。新規にユーザーを登録するにはメールサーバの設定とかもしておかないといけなさそうなので、ひとまず初期設定されているログインID で逃げます。
# mst_users テーブルの login_id を見て、パスワードは勘で。
ninearrows/ninearrows
ログインするとプロジェクト作成画面になります。まぁ、プロジェクト管理アプリでプロジェクトがなかったら意味がないのでそりゃそうかって感じです。プロジェクトのテンプレートは「システム開発系」と「WEB製作系」の2つから選べます。前者を選んでおきます。
プロジェクトを作成すると、Todo、Event、Information、Member で 4分割された画面が開きます。これが DashBoard のようですね。同列のメニューには、WBS、Gantt、Calendar、File が並びます。それらの上でプロジェクトがタブ形式で複数並べられるようになっているので、マルチプロジェクト管理ができるんでしょう。(完全に見た目だけから機能を追っています)
DashBoard の画面は参照オンリー。
WBS 画面には先ほど選択したテンプレートで WBS がすでに描かれています。項目は、タスク、担当者、期限、状況、依頼者。ドラッグ & ドロップで列の並びは入れ替えられます。タスクの項目には、マイルストーンとイベント、そしてただのタスクが追加できます。また親タスクをクリックすることで子タスクがトグルできます。
{kind=link}
Gantt の画面は、WBS の画面と同じ縦軸で横軸が時間になります。Gantt からでも WBS からでも同様に担当者や期限の編集はできそう。逆に両方を並べて見たいとなるとつらいのかな。
{kind=link}
Calendar はそのまんま。タスクやマイルストーンの追加はここからでもできます。ただし、Google Calendar ほどの操作性はないみたい。
{kind=link}
Files の画面では、ファイルを管理できます。フォルダ構造もとれるのはいいが、SCM と連携しているわけではないです。ちなみにフォルダはつくれましたが、なぜかアップロードはうまくいきませんでした。アップロードしたファイルは 9arrows_home/public/files にはいるはず。素直に SCM と連携してリポジトリブラウザみたいな画面にしちゃえばよかったのにと思うのですが..。
{kind=link}
ざっとこんなところだと思うので、最後に ERD も眺めてみます。
- 9arrows's ERD
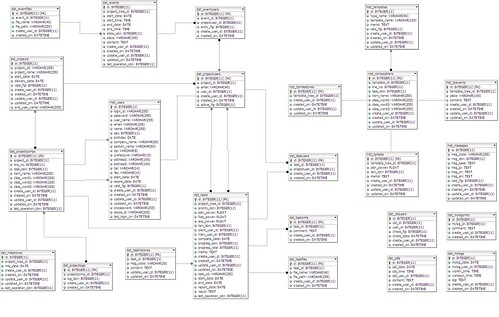
テーブル数はそれほど多くないですね。ひとまず今日はここまで。
# 9arrows は GPLv3 なんだよなぁ... (^^;
参考
- ベーシスト兼ソフトウェアエンジニアのブログ 9arrowsを使ってみる。。。あれ?うむむ。
- 改善したらよいポイントの提示
- 9arrowsをさっそく改造 | nautilus note the Room
- コメントもよい
- 9ArrowsをMySQLで入れるのと便利な改造 | nautilus note the Room
- 記事内容が消えているので Google キャッシュから
- タスク共有やプロジェクト管理が可能でガントチャート表示もできる国産オープンソースツール「9Arrows」を使ってみた - GIGAZINE
- screenshot が充実
Redmine の ERD を描いてみました
ちょっと前に Redmine を調べていたので載せておきます。機能としての特徴は書籍もいくつか出ているので、それらを参考にしながら触ってみればよしとして、書籍にないもう少し実装よりのところが気になるものです。
バージョンは以下のとおり。
% svn info
URL: http://redmine.rubyforge.org/svn/trunk
リポジトリ UUID: e93f8b46-1217-0410-a6f0-8f06a7374b81
リビジョン: 2819
まずは全体感を把握しようと、RailRoad を試してみました。Graphviz も忘れずにインストールしておきます。
% gem install railload % cd redmine_home % railroad -o controller.dot -C % railroad -o model.dot -M % neato -Tpng controller.dot > controller.png % neato -Tpng model.dot > model.png
できあがった図はこんな感じです。RailRoad のオプションを変えるとラベルを追加できたり、他にもいろいろできますが、まぁこんな感じ。
- controller.png

- model.png
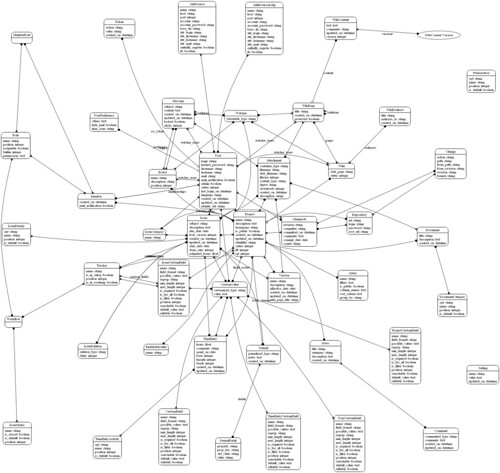
コントローラはともかくとして、モデルはもうちょっと見やすくしたいです。
ひとまず MySQL 向けに migrate しておいて、DB Designer でリバースエンジニアリングしてみました。で、これだけだと関連が何も描かれないので、モデルの has_many や has_one、belongs_to なんかを見ながら関連を加えてみます。そしてできあがったのが、以下の ERD。エンティティの位置も適当に動かして、少しすっきりさせてみました。
- ERD
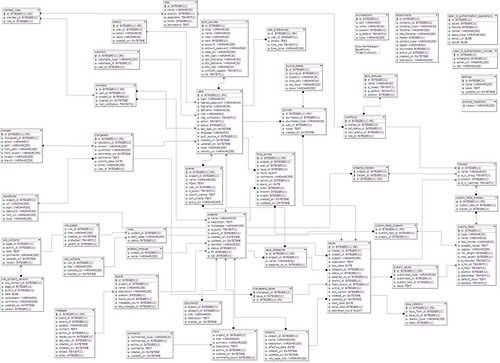
あとは、Redmine を適当に動かしながら、レコードの生成具合いを見てみます。(まぁ、直接コードだけを追ってもいいのかもしれませんが、地道に遠回りしてみました。)
ユーザー登録
- ログイン登録すると、users テーブルにレコード生成
- 管理者に承認されると、ステータス (下記参照) が 2 から 1 に変化
- auth_sources は LDAP 連携とかしたときに利用されるみたい
- ちなみにデフォルトだと登録しただけじゃ、ユーザーはアクティブにならない
class User < ActiveRecord::Base # Account statuses STATUS_ANONYMOUS = 0 STATUS_ACTIVE = 1 STATUS_REGISTERED = 2 STATUS_LOCKED = 3
ユーザー承認
- ユーザー管理画面から「有効にする」
- URL はこんなん
- http://localhost:3000/users/3/edit?status=&user[status]=1
- これで users テーブルのステータスも ACTIVE に変わる
権限管理
- 種類は以下の 5つ: NonMember、Anonymous、管理者、開発者、報告者
- ロールはメンバーに対して複数指定できる
- roles テーブルの permission カラムに yaml 形式でつっこんである
- code review tools を導入したときは、plugin の migration を流すと管理者や開発者の permission に追記されている
- 余談ですが、code review tools の日本語化は中途半端
- ロール -> 開発者 とかで開くと英語表記のまま
プロジェクトの作成
- projects テーブルにレコード生成
- 選択したモジュールも enabled_modules にレコード生成される
プロジェクトへのメンバー登録
- members テーブルにレコード生成
- 付与したロール分、member_roles テーブルにレコード生成
チケットの登録
- issues テーブルにレコード作成
- category_id はデフォルトでは null
- カテゴリをあらかじめ用意しとけば、選択時にここに値がはいる
- カテゴリはトラッカーごとには分けられない
- マイルストーンを定義してあると、fixed_version_id が設定される
- チケット監視者にチェックしとくと、watchers テーブルにもレコード生成
時間を記録
- time_entries テーブルにレコード作成
- チケットの経過時間の値が更新されることになる
関連チケットを追加
- チケットを作成してから、わざわざ関連づけしないといけないのがちょっとめんどい
- issue_relations テーブルにレコード生成
- issues テーブル上の変更はとくにない
チケットのカテゴリを追加
- issue_categories テーブルにレコード生成
チケットの編集
フォーラムの追加
- boards テーブルにレコード生成
(フォーラムで) メッセージの追加
- messages テーブルにレコード生成
- parent_id は返答元の message_id
- reply_count もインクリメントされるし、last_reply_id も更新される
- sticky カラムはなんだろ?
チケットへの添付ファイルの追加
- 添付ファイルが空のファイルだと無視されるが、そうでないと↓
- journal_details にも変更が記録される
- attachments テーブルにレコード作成
- container_type は "Issue" になった
- container_id は各タイプのモデルにおける id (ここでは issue_id の値をさす)
- ちなみに文書への添付ファイルの追加だと、container_type は Document
- 添付ファイルは REDMINE_HOME のfiles 以下にファイル名に prefix をつけて格納される
- これは文書やそれ以外での添付のときでも同じ
- 「添付ファイル」というメニュータブからの添付は、プロジェクトとしての成果物の公開のためっぽい
- プロジェクトのバージョンを指定して公開できる
文書の登録
- documents テーブルにレコード生成
- 前述のとおり、attachments テーブルにもレコード生成
カスタムフィールドの追加
- custom_fields テーブルにレコード生成
- possible_values には Yaml 形式でつっこまれている
カスタムフィールドの編集
- custm_values テーブルにレコードが生成
- カスタムフィールドの値として入力/選択した値がはいっている
- customized_type は attachments テーブルの container_type と似てる
- customized_id は対象となる user_id だったり issue_id だったり
- カスタムフィールドは、プロジェクトやユーザー、チケットなどを対象に追加できる
バージョンの追加
- プロジェクトの設定でバージョンの追加
- versions テーブルにレコード生成
- チケット作成/更新のときに、対象バージョンを設定できる
- バージョンを 1つでも追加すると、ロードマップのメニューが増える
カスタムクエリの追加
- チケットの絞り込み用のクエリ
- ユーザーごと、プロジェクトごとに作成可能
- queries テーブルにレコード生成
- filter カラムに Yaml 形式で条件がはいる
wiki のページ名の変更
- wiki_redirects テーブルにレコード作成
あとは、Subversion や Git などの SCM と連携させると、repositories テーブルにレコードが生成されたり、トラッカーを追加したら trackers テーブルにレコードが生成されたりします。また、GUI からチケットの承認フローを編集すれば、workflows テーブルが書き変わります。ちょっと変わっているのは enumerations テーブルで、チケットの緊急度やドキュメントの種類、アクティビティなどのデフォルト値がまとめて書かれてたりします。
ざっとこんな感じですが、テーブルの構造や役割がはっきりしているとコードも頭に入りやすいと思います。と言うのは古いのかもしれませんが...? (^^;
機能や導入、運用あたりについては以下を参考に。

- 作者: 倉貫義人,栗栖義臣,並河祐貴,前田直樹
- 出版社/メーカー: インプレス
- 発売日: 2009/07/24
- メディア: 単行本
- 購入: 6人 クリック: 245回
- この商品を含むブログ (31件) を見る

- 作者: 前田剛
- 出版社/メーカー: 秀和システム
- 発売日: 2008/11/26
- メディア: 単行本
- 購入: 4人 クリック: 129回
- この商品を含むブログ (48件) を見る
実践的オブジェクト指向分析・設計と実装 (続き その2)
最終日は昨日より難易度の高い例題でほぼ 1日演習でした。対象は自動通話分散システムで、複数のオペレータと外線が登場し、レースコンディションの発生する問題でした。
最初からほとんどアドバイスのない状態で 2人 1組でモデルを考えていきます。途中ランチにもでたので、分析/設計に要した時間は 3-4 時間ほどでしょうか。途中間違った方向にも進みましたが、最終的にはなんとか実装に落ちる設計にたどり着けました。
一見長いようにも感じますが、すっきりした設計にしあがり、ユースケースを満たす上で疑問になる部分がすべて解消されているので、実装に落とすのはけっこう機械的な作業になります。最初に時間はかかりますが、手戻りが少ない分、作業に無駄がないですし、分析/設計に自信ももてます。
分析/設計において重要だったのは、初日からのキーメッセージどおり、
- オブジェクトレベルで考え、
- ユースケース実現の詳細度をあげる
に尽きました。オブジェクトレベルで多重度、関連を具体的にイメージし、無駄のないもたせ方を検討します。そして、ファンクションがコールされる流れをイメージし、ユースケースがちゃんと満たされていくことを確認します。
文章にしてしまうとこれだけなのですが、実際に演習を通じて手と頭を動かしてみると、なかなか思うようにはいかないです。
もっと素振りをして身体に馴染ませる必要がありますね... (^^;
以下は、初日からのメモの抜粋です。
講義の隙間隙間で先生がいろいろな話をしてくださったので、それを含めてのメモです。
- ラーニングツリーの講座
- 多重度
- B -----> A
- 0..* 0..1
- 左: 任意の A のオブジェクト 1つ "を" 参照する B のオブジェクトががいくつあるか
- 右: 任意の B のオブジェクト 1つ "が" 参照する A のオブジェクトがいくつあるか
- オブジェクト指向分析
- RUP
- 仕様と分析/設計
- 仕様は「what」で、分析/設計は「How」
- 正しい/正しくないは、仕様に対しての実装
- 仕様自体に正しい/正しくないはない、あるのは良い/悪いくらい
- 良い/悪いは教育しにくい (フィードバックをかけづらいので)
- ある意味才能、その才能をもつ者の発想をいかに早く実現するか
- 機会損失
- やる/やらない、いずれも決定
- やらないという決断をした場合の機会損失も当然ある
- 日本ではやると決断したときの責任だけ追求、だから皆やらない
- ユースケース分析/設計
- 上流下流の分離
- 工場ではうまくいっていたので、丸投げ文化の助長
- システムではうまくいかない
- 難しい部分を実装までアーキテクト、それ以外を開発者
- Life is beautiful: ソフトウェアの仕様書は料理のレシピに似ている
- 多態性
- オブジェクトはインテリジェンスをもっている
- 結合度を下げるためにメッセージパッシング
- 作家
- 小さい頃にどれだけ本を読んでいたかが重要
- 書くことは重要ではない
- むしろ、早くから書き過ぎると型にはまってしまう
- プログラムも同様、綺麗なソースをたくさん読みましょう
- アーキテクトの立ち位置
- PM でない
- PM とツートップの権限
- リスクを見つけられないひとがリスクの管理をしてもだめ
- 管理部門からの心からのサポートが必要 # ここが日本で弱い
- フィードバックを受け入れる
- PM でない
- フェーズ
- 方向付け (ビジネス観点、アウトライン、機能の選択)
- 推敲 (アーキテクチャの決定、計画/費用の見積り)
- 作成
- 移行
- とくに方向付けでは、分野ごとの専門家が集らないと本質的な問題の解決には至らない
- テスト
- 契約
- 最初に詳細なユースケースまではやはり決まらない
- 実装をはじめてから擦り合わせていくことも重要
- ここで上下関係がはいってきてしまうのが日本
- 米国の場合は、契約で縛ってしまう
- 両者の中間的なところが落とし所か..
- スーパースター
- 理論的な知識、バックグラウンド
- どんな環境でも動かす
- スーパースターを育てる、権限を与える
- 自分で提案して、自分で開発 (アイデアを具現化する能力)